Sat 07 December 2019
Privacy, data rights and ownership are hot topics in 2019. The increased focus on these topics grew over the past few years from a few different things. Snowden's 2013 leaks showed the general public that the data you put out there is not as private as once assumed. An increasing number of database leaks over the past few years have made more people aware that not all data on the internet is necessarily safe and secure. Europe's General Data Protection Regulation (GDPR) woke many companies up to legal liabilities of not taking this stuff seriously, and an increasing number of countries and locales are starting to follow suit (examples include Japan's Act on the Protection of Personal Information (APPI), becoming more restrictive, and California pushing through with the California Consumer Privacy Act (CCPA)).
This is all generally net good for consumers. It pushes forward towards building products that have more respect for users and their rights, and normalizes the conversation in the public eye. However, there's an interesting area of study that I haven't seen as much attention paid to, though - back in the early years of the iPhone and App Store, there was an explosion of apps released that took user data and withered on the vine, to to speak. What happened to the data these apps held and had access to?
I started looking at this for an app I had personal experience with: Couple.
What is (or was) Couple?
Couple (originally branded at launch as "Pair") was an app that debuted in the 2012 Y Combinator batch. The general target market was people in relationships: a supposedly closed off, intimate place to chat, leave media, notes, drawings, and thoughts for each other, along with a shared calendar and a map to send each other your location. It described itself in 2014 with the following text:
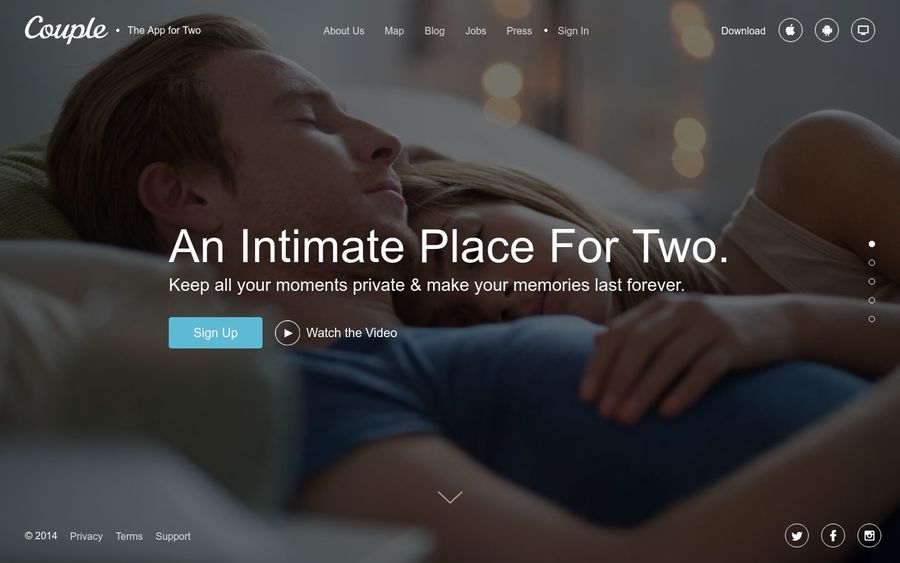
An Intimate Place for Two.
Keep all your moments private & make your memories last forever.
You might be thinking to yourself: why would anybody use this? Well, remember that this was 2012 - a few years into the App Store, where various social networks and services were still fighting it out. The appeal of having a special app on your homescreen to differentiate your partner from the myriad of other chats and social networks was very enticing. It launched on Android as well, so it found a decent enough market of connecting people across the two platforms (over 4 billion downloads and seemingly billions of messages).
Now, back in 2012, I was fortunate enough to have met the woman who'd eventually become my wife. She was studying overseas, and I was on a business trip. We started dating. It became a situation that will sound familiar to many people: long distance, an excruciatingly annoying experience when you're utterly infatuated with someone. An app like Couple seemed like a great idea - a way to put more of an emphasis on the relationship than another chat line in your app of choice.
We used it until we were no longer long distance. The app eventually disappeared from the App Store, and while the servers would periodically crash, it seemingly still worked - I know I was able to sync the data to my current phone, and apparently people were using it as late as this year.
Others, like me, wondered about what actually happened to all the data that was on Couple's servers. Note that this thread has a comment mentioning the service had been hacked - I've been unable to verify that this was the case, and as it's one comment on one thread I'm inclined to not believe it until determined otherwise. Take it with a grain of salt.
So what happened here?
If we try to trace this, a few things become apparent:
- Couple launches in 2012, under four cofounders.
- Around October 2014, three of the four cofounders leave to go work at Dropbox.
- On Feburary 12th, 2016, Couple was acquired by Life360, a company focused on providing a "family network" experience. It seems like an acquihire, and after looking around some of the former Couple staff still work there.
- On June 27th, 2018, Couple was apparently transfered or sold without much fanfare (seriously, this tweet is all I could find).
- I contacted Life360 via Twitter on Dec 6th, 2019. They state, accordingly, that they have no relationship with the app anymore, and refer you to contact [email protected].
- The company that Couple was transfered to is Coupleapp, Inc. According to that business filing, the founder is Corey Wiles (@kwylez on Twitter). He's the creator of a an app known as "Significant Other", that has similiar goals to those of Couple originally.
- According to his website, he was a contractor at Life360 for a period.
- Emails to the Couple support email ([email protected]) go unanswered. Poking on Twitter similarly goes unanswered. The website has not been updated since the original owners (Tenthbit, Inc) had posession of it.
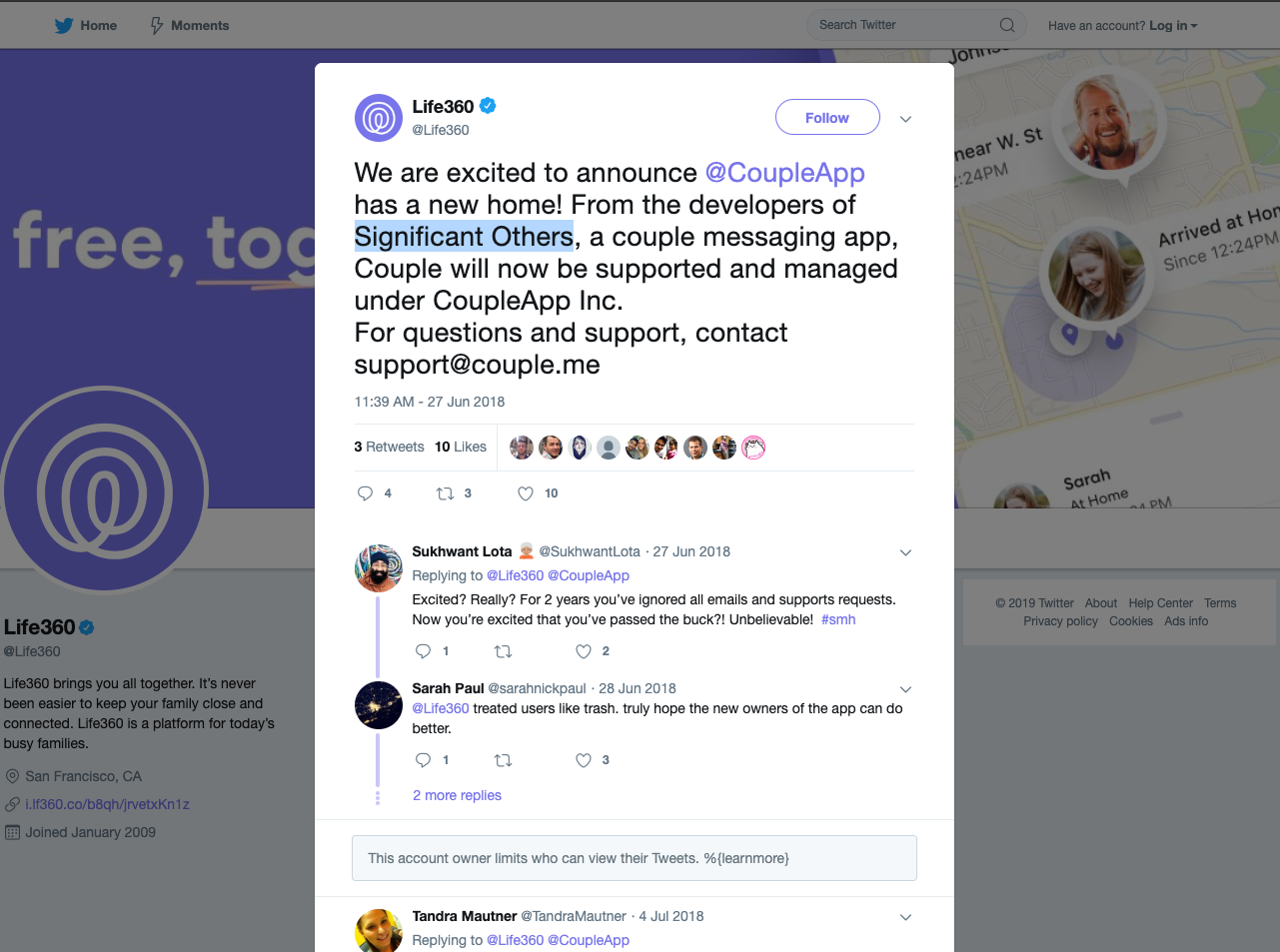
Now, it's important to state this: the data sent over and stored on Couple's servers was often very personal data. To the best of my knowledge, and having searched quite a bit, there's never been any communication from any owner of Couple regarding what exactly happened to the data. The service 503's now; if you try to delete your account or data from within the app, it simply won't work. Some might consider this to mean it's just gone, but if you've built any service like this, you know very well that there's a real possibility the data is still sitting on some S3 bucket somewhere.
Why on earth is it acceptable that Life360 can spin this back out without any notice beyond a quick tweet? It blows my mind that this just happened without much notice or coverage.
What to do from here?
So, here's the thing - I'm absolutely, totally fine with the service shutting down. I'd just like to know what happened to the data that was held by this service. Former users who trusted the service with their data deserve to know if the new owners were given everything; a transfer like that is not something that should be announced over Twitter alone. The type of content or data that's involved here is very personal in nature - personal thoughts, photos, videos and more.
Furthermore, in a world of GDPR, CCPA and so on, I'd love to know: where does something like this fall? Considering the download numbers that this app did, and given that it was available worldwide... I have to think that it absolutely falls within the realm of GDPR. CCPA comes into enforcement on January 1st, 2020 - around 3 weeks from time of writing this. When the new entity doesn't respond, what's next? Kick this up the chain to state or national agencies?
If someone involved in the app could publicly clarify what exactly happened here, it would do every former user a world of good.
Ultimately, it's worth remembering that the focus on privacy and user rights that we have today weren't always at the forefront years ago. Many services existed then that might still contain your digital footprint, and it's good to review and take stock of these. You don't always know where your data wound up.
Thu 01 August 2019
Miss the old Reddit browsing experience? You're not alone. While I've no doubt that they'll eventually produce something really smooth and cool (they're too good of an engineering team not to), in the meantime I've found myself preferring to use the old Reddit design. It's sleeker, faster to load, and easier to skim large amounts of posts with.
You can set your preference in your profile to use the old Reddit design, but I've noticed that it doesn't automatically push you to it - you'll still wind up waiting for a behemoth of a UI to load if you click a random Reddit link while not on old.reddit.com already. Chrome and Firefox have convenient extensions to force-rewrite the URL, but Safari is lacking... maybe due to the APIs being different, or maybe due to the up-front cost for the developer program.
At any rate, I wanted that extension in Safari, so I ported it over. I call it "Oldr for Reddit", and you can download it here. Once it's installed, check your Safari preferences -> Extensions list and enable it, and it should "just work" from there.
Privacy Policy and Terms of Service
The software is released as-is, and by using it, you agree that you understand this. I don't record ay data, and have no analytics beyond anything Apple gives me in terms of download numbers. If you find anywhere that I've errored in this, get in touch.
Questions or comments? Feel free to email me or catch me on Twitter.
Wed 05 June 2019
At WWDC this year, Apple announced a new feature for user registration with applications. Called simply "Sign In with Apple", it's effectively an OAuth2 authentication ritual similar to what Facebook, Google, Twitter (and more) currently offer. The catch is that Apple wants to do it in a way that protects your privacy, by acting as an in-between agent to avoid your email address being used for spam, data targeting or profiling, and more. It's really significant, since a company the size of Apple pushing this could enable it to take off in a way that just wouldn't happen elsewhere.
However, I've noticed more than a few people throwing comments around the web to the tune of:
- "I already do this by providing a fake email, like
[email protected], to everyone!"
- "I'm protected already because I run my own domain with a catch-all email, like
[email protected]!"
These imply that what Apple is doing is easily replicated, which is somewhat far from the case. Let's examine why.
The Special Email
You sign up to a provider for some service that you just want to scope out, and you're worried about the safety of it. You use Gmail, so you decide "let's just give it a special one that I can block later, like [email protected]". Later on the service database leaks. You're safe, right?
Not so much. Removing the special character bits from Gmail is not inherently difficult, so matching your email across database dumps becomes relatively straightforward for any cleaning script worth its salt. You can block all the emails coming from that special email, but nothing is stopping you from getting them... and nothing is stopping the provider from emailing your real one, which as noted, there's a good chance they've got now. Linking your data sets together for profiling is also relatively easy at this point.
How's this change with Apple's approach? When you sign in with Apple, you get assigned a special email address that acts as a relay to your true email. Reading the documentation further, this becomes even more useful than it sounds - to send email via that relay, it has to come from a domain that the developer explicitly proves they control. Anything else is outright ignored. This means that, should database leaks occur, you have a per-app-unique email that can't be tied across leaks, and can't be arbitrarily emailed or spammed. It's providing privacy in a way that your home-grown special email case simply can't.
The Catch-All Email
So you're savvy enough to run your own domain-based email, and you decide "alright, let's just use a [email protected] email and weed out the bad actors this way". This works slightly better than the special email case above, but at the end of the day, I'm going to be honest with you: I've seen more than my fair share of data cleaning scripts, and if your domain isn't a known email provider, you're just going to be attributed as the same user across leaks. You're not big enough to matter to a bad actor, and it's easy enough to lump anything matching your domain together. You're still going to be profiled if you go this route.
Big-Corp?
The other thing I keep seeing come up is paranoia around big corporations being the one to vend out these solutions. This is also sometimes phrased as "privacy shouldn't come at a price". This is correct, it shouldn't... but Apple should be applauded for this move, because your home-grown solution isn't actually doing anything to solve the bigger issue. Apple didn't invent email relays, privacy tools, or what have you, but they're able to push them at a scale that forces the tech industry to change for the better.
We will not move past this era of user-targeting unless there's a big entity that steps in, be it government regulation (seemingly, currently, unlikely) or a large corporation with enough muscle to make it happen (in this case, Apple). Dislike them for whatever reason you want, but they really do deserve credit for being willing to stand up and push this issue.
Wed 15 May 2019
When did redesigning a personal website become such hell? I've had this site running for almost two decades now, and while it's been a point of (perhaps misplaced) pride, I try to keep it looking decent and up to date. The modern landscape is crazy, though - a million-ish screen sizes and densities, different appearance APIs depending on whether you're running a dark mode or not, and much higher standards for what "looks good".
I think I settled on something I'm happy with for the next few years, and with any luck, the remainder of my time on these here internets.
RYMC 4.0
The previous design for this site was made towards the tail-end of my time living in Tokyo. I realized one day that I'd kept the design from... 2008... up for almost ten years. We're talking pre-iPhone here. I redesigned it to effectively look like a Medium blog with some elements of personality, and was happy with it for awhile: it did the job and stayed out of my way.
Then earlier this year, a family member was unfortunately diagnosed with cancer. Sitting in a hospital room with someone you care about while they battle something like that isn't easy - it makes you think a lot about how you live your own life. I remember pulling up my site one day and thinking to myself: "wow, this is incredibly devoid of personality. Is this mine?"
Since I had time to pass while sitting there, I just kind of started throwing stuff at the screen and seeing what I liked.
- I wanted something with dynamic-ish shapes. A growing current trend in (web-based) design is softer shapes and more variation in element positioning.
- I wanted to keep it loading insanely fast. I personally like a CSS-Zen-Garden approach (I'm dating myself here) to see what all can be done without needing a litany of network connections.
- I wanted to spruce up the old content, for better SEO and reading comfort.
- I wanted to support dark mode, for browsers that support the new
@media query for appearance preferences.
- I wanted a smooth code reading experience, for the more technical articles.
- I wanted personality in here somewhere.
Activity Feed(s)
That last point dovetails into the other big thing I wanted. The web I grew up on was people owning their content, and we lost that somewhere along the way. It's a difficult thing to walk back, too, but I figure I can at least have it for myself - hence why this site now automatically grabs my tweets, GitHub activity, and Dribbble work and displays it throughout as you browse. In keeping with ensuring this thing loads like demonically fast, the data is scraped and repackaged into what's effectly a static site every few minutes.
If you're interested, I open sourced the code I used for this part here. Feel free to use!
Moving Forward
I'm hoping to continue posting content here, since it's nice to have your own space. 2019 has been a pretty good clip for this! Also, never let me do this again.
Thu 07 March 2019
I've been using Vim for a little over ten years now. Up until Vim 8, I'd go so far as to say little changed for me... but Vim 8 actually changed the game in a pretty big way. The introduction of asynchronous jobs that can run in the background enables functionality like code linting and completion that don't block the editor, a rather stark contrast to the old days. In fact, I outright didn't bother with code completion and the like prior to Vim 8 - it was never fast enough and just left me too annoyed to care.
Anyway, thanks to this new functionality, we can use projects like ALE to provide smooth linting, autocompletion, fixing, and so on. Setting up this and other Vim plugins is a bit outside the scope of this post, but I'd highly recommend it if you haven't tried it. ALE includes support for LSP (language-server-protocol), originally developed by Microsoft and now supported by a litany of editors and IDEs. This support has made Vim feel like far less of a black-box at points!
ALE and Docker
One thing I ran into when setting ALE up was that various projects have their own rules. For example, a Japanese company I help has some rather peculiar style rules for their Python codebase. I recently converted their infrastructure to a Docker-based architecture, and as a result all Python code executes inside a virtual machine (at least, insofar as MacOS/Windows are concerned - Linux users might have a slightly easier time here!).
In most cases, this is not too big of a problem - however, this particular case means that tools like flake8 are running inside the VM, and not in the userspace where you'd be running Vim. In the issues I glanced over, the author of ALE recommends just running Vim over SSH into the VM, which can be an alright solution... albeit a bit clunky, given your setup for Vim runs on your local machine. We really just need a way to communicate between the two layers, right?
This is actually possible with just a bit of extra configuration work. We'll need two things before we can make it work, though:
- If you haven't already, I recommend setting up your Vim installation so that it supports some kind of local .vimrc setup. I use embear/vim-localvimrc and whitelist the projects I know are safe, but you do you.
- A custom shell script to act as the bridge between Docker and the host environment.
The Shell Script
This is much simpler than you'd think! Somewhere in your project, edit and throw the following:
#!/bin/bash
docker-compose exec -T {{ Your docker env name here }} flake8 $@
This is inspired by acro5piano's post over on qiita, but fixed up slightly to work with what I presume are recent changes in Docker and/or ALE. Notably, our command has to specify -T to stop Docker from allocating a pseudo TTY. Save this and mark it as executable, and ensure your Docker environment is running if you want ALE to report errors.
(I also figured I'd throw this post up in English, just so the knowledge is a bit more freely available)
Local .lvimrc Configuration
With the shell script in place, we just need to instruct ALE on how to call flake8. If you're using vim-localvimrc, you can throw a .lvimrc in your project root with the following:
let g:ale_python_flake8_executable = '/path/to/flake8/shell/script'
Provided you did all the above correct, flake8 should now be properly reporting to ALE. You'd need to do this setup per-project, but to be honest I don't find it that annoying, as I find Docker is worth it over the old-school Virtualenv solutions. If you know of a better way to do this, I'm all ears!
Mon 18 February 2019
If you're trying to compile code on recent versions of macOS, and it tries to link to OpenSSL, you may find yourself driven a bit mad by how odd it all is. The long and short of it is that Apple, in a recent-ish release, removed the headers for their version of OpenSSL, and you need to install a modern version of OpenSSL via Homebrew. This is really straightforward... but won't, in some cases, automatically make your project compile.
This was the case for a project I was working on, which happened to be written in Rust. The resulting errors spewed from Cargo were, after parsing, pretty clear: it was trying and failing to find and link to an OpenSSL installation. This can be confusing to diagnose and fix, since over the years Rust moved pretty quickly, and there's a litany of strange GitHub issue threads devoted to the issue. It crosses over with some macOS issues, and... yeah.
Thus, I'm going to dump my .bashrc fixes here. Throwing the following in your bash profile, then running a cargo clean + build should get your project compiling.
export OPENSSL_ROOT_DIR=$(brew --prefix openssl)
export OPENSSL_LIB_DIR="$OPENSSL_ROOT_DIR/lib"
export OPENSSL_INCLUDE_DIR="$OPENSSL_ROOT_DIR/include"
export LDFLAGS="-L$OPENSSL_ROOT_DIR/lib"
export CPPFLAGS="-I$OPENSSL_ROOT_DIR/include"
export PKG_CONFIG_PATH="$OPENSSL_ROOT_DIR/lib/pkgconfig"
export LIBRARY_PATH="$LIBRARY_PATH:$OPENSSL_ROOT_DIR/lib/"
Exporting these flags ensures that Rust, Cargo, LLVM and crew correctly grok where to find OpenSSL to link against. Hopefully this helps someone else out there, since this can be annoying to diagnose! Some tweaking may be needed depending on how you have your system configured.
Thu 31 January 2019
Some time ago, I read an interesting article from The Guardian about their work with a concept they call "Live Notifications". The general idea is being able to do more with push notifications, turning them into a rich experience with dynamically generated or updated assets. I experimented with this on my own when I wanted a simple way of charting some personal data; I have a server that periodically checks a source, and notifies based on updated findings (yes, this is as generic a description as it can get - it's personal). Rather than generating and storing images on a server that'd only be needed once, couldn't I just dynamically generate them client side?
Turns out, it's not super complicated in the grand scheme of things. Using an iOS Notification Content Extension or iOS Notification Service Extension, it's possible to have a lightweight process running that can act dynamically on received push notifications. This is the key - we'll send a lightweight payload via Apple's Push Notification Service (APNS), and then build and attach an image to the notification before it displays.
Limitations
There are, surprisingly, not too many limitations... but there's one or two to know about.
- Usage of portions of
UIKit is pretty much impossible - for instance, UIApplication is out, but you can use CoreGraphics et al as necessary.
- The memory limitations are much smaller and the system is more aggressive in killing your extension if you're not careful, so it's best to keep this efficient. I'd highly recommend sending a default notification with usable title and text, and then customize it as necessary when you do the image.
- If you want to access
NSUserDefaults, you'll need to ensure you're using an App Group to communicate between processes properly, as the extension lives separately from your app.
- Oh, and if you use Realm, it's a little tricky to read data in extensions (as of writing this, I don't believe it works properly). I've only used this in situations with
NSUserDefaults, Core Data, or SQLite. I'm sure there's a method for Realm, but you're on your own for that.
Building the Extension
For this example, we'll assume you have an iOS app that's properly configured for push notifications. If you're unsure of how to do this, there's enough guides around the internet to walk you through this, so run through one of those first. The example below also makes use of the excellent Charts library by Daniel Gindi, so grab that if you need it.
We'll start with a standard iOS Service Extension, and wire it up to attempt producing an image in the didReceive(...) method. We'll implement three methods, and support throwing up the chain to make things easier - it's less ideal if an extension crashes, because getting it restarted is... unlikely. We'll simply recover "gracefully" from any error, but due to this it's also worth getting right in testing.
import UIKit
import UserNotifications
import Charts
class NotificationService: UNNotificationServiceExtension {
var contentHandler: ((UNNotificationContent) -> Void)?
var bestAttemptContent: UNMutableNotificationContent?
override func didReceive(_ request: UNNotificationRequest, withContentHandler contentHandler: @escaping (UNNotificationContent) -> Void) {
self.contentHandler = contentHandler
bestAttemptContent = (request.content.mutableCopy() as? UNMutableNotificationContent)
if let bestAttemptContent = bestAttemptContent {
bestAttemptContent.title = "\(bestAttemptContent.title) [modified]"
do {
buildChartAttachment(request)
} catch {
// Assuming you sent a "good enough" notification by default, this should be
// safe. We can log here to see what's wrong, though...
print("Unexpected error building attachment! \(error).")
}
contentHandler(bestAttemptContent)
}
}
override func serviceExtensionTimeWillExpire() {
if let contentHandler = contentHandler, let bestAttemptContent = bestAttemptContent {
contentHandler(bestAttemptContent)
}
}
// The three main methods we'll implement in a moment
func renderChartImage() -> UIImage? {}
func storeChartImage(_ image: UIImage?) throws -> URL {}
func buildChartAttachment(_ request: UNNotificationRequest) throws {}
}
Rendering the Chart
For the sake of example, we'll make a very basic LineChart using bogus data. In a real world scenario, you'd want your data to fit into the space of a push notification (2kb - 4kb, which is actually a good amount of space). You could also use a different type of chart, if you wanted. The use cases here are pretty cool - imagine if RobinHood allowed you to, say, see a chart at a glance of how your portfolio is doing. Depending on the performance, that chart could change color or appearance to convey more information at a glance.
Granted, you might not want that much information being on a push notification. Maybe you have prying eyes around you, or something - privacy is probably good to consider if you're reading this and looking to implement it as a feature. The chart below has some settings pre-tuned for a "nice enough" display, but you can tinker with it to your liking.
func renderChartImage() -> UIImage? {
let chartView = LineChartView(frame: CGRect(x: 0, y: 0, width: 320, height: 320))
chartView.minOffset = 0
chartView.chartDescription?.enabled = false
chartView.rightAxis.enabled = false
chartView.leftAxes.enabled = false
chartView.xAxis.drawLabelsEnabled = false
chartView.xAxis.drawAxisLineEnabled = false
chartView.xAxis.drawGridLinesEnabled = false
chartView.legend.enabled = false
chartView.drawGridBackgroundEnabled = true
chartView.drawBordersEnabled = false
chartView.setScaleEnabled(false)
chartView.contentScaleFactor = 2
chartView.backgroundColor = UIColor.black
chartView.gridBackgroundColor = UIColor.green
let dataSet = LineChartDataSet(values: [
ChartDataEntry(x: 1, y: 2),
ChartDataEntry(x: 2, y: 5),
ChartDataEntry(x: 3, y: 7),
ChartDataEntry(x: 4, y: 12),
ChartDataEntry(x: 5, y: 18),
ChartDataEntry(x: 6, y: 7),
ChartDataEntry(x: 7, y: 1)
], label: "")
dataSet.lineWidth = 4
dataSet.drawCirclesEnabled = false
dataSet.drawFilledEnabled = true
dataSet.setColor(UIColor.green)
dataSet.fillColor = UIColor.green
let data = LineChartData(dataSets: [dataSet])
data.setDrawValues(false)
chartView.data = data
return chartView.getChartImage(transparent: false)
}
Note that the size of the chart is hard-coded, and that the scale is manually set. Both are critical for pixel-perfect rendering; the logic could certainly be better (e.g, larger phones really need the scale to be 3), but the general idea is showcased here.
Storing the Image
We now need to attach the image to the notification. We do this using a UNNotificationAttachment, which... requires a URL. Thus, we'll be writing this to the filesystem temporarily. This method attempts to create a temporary directory and write the PNG data from the chart image returned in our prior method.
func storeChartImage(_ image: UIImage?) throws -> URL {
let directory = URL(fileURLWithPath: NSTemporaryDirectory(), isDirectory: true)
try FileManager.default.createDirectory(at: directory, withIntermediateDirectories: true, attributes: nil)
let url = directory.appendingPathComponent("tmp.png")
try image?.pngData()?.write(to: url, options: .atomic)
return url
}
Note that, in my testing, simply writing to the same URL over and over again didn't impact multiple notifications - i.e, you're not overwriting an old image that might be on the screen. I've no idea if this will change in later iOS revisions, though, so keep it in the back of your mind!
Putting it all together
With the image saved and ready, we can attach it to the notification and let the system display it to the user.
func buildChartAttachment(_ request: UNNotificationRequest) throws {
let chartImage = renderChartImage()
let url = try storeChartImage(chartImage)
let attachment = try UNNotificationAttachment(identifier: "", url: url, options: nil)
bestAttemptContent?.attachments = [attachment]
}
And voila, you now have a dynamically generated chart. No need to worry about rendering images server side, storing and caching them, or anything like that!

Your chart hopefully looks better than this demo image I found laying around from my test runs. :)
...surely there must be a catch...
Yeah, there's a few things to consider here.
- You're technically pushing the processing requirements to the user's device, but in my testing, this didn't cause significant battery drain over time. If you opt to do this, consider the time interval that you're pushing notifications on.
- As mentioned before, you should design notifications such that they're sent "good enough", in case a notification extension crashes or is killed by the OS for whatever reason. This means ensuring a good default title, body, and so on are sent.
- If you use this for financial data, which would not surprise me as the chief interest here, you should consider making this feature "opt-in" rather than "opt-out". Charts can convey a lot more than text at a glance, and people might not want their information being blown out like that.
But with that all said, it's a pretty cool trick! Due credit goes to The Guardian for inspiring me to look into this. If you find issues with the code samples above, feel free to ping me over email or Twitter and let me know!
Wed 02 January 2019
Recently, I had a friend ask me to glance at some data science work he was doing. He was puzzled why his output, upon attempting to send it to a remote server for processing, was crashing the entire thing. The project was using a pretty standard toolset - Pandas, Numpy, and so on. After looking at it for a minute, I realized he was running into a JSON encoding issue regarding certain data types in Pandas and Numpy.
The fix is relatively straightforward, if you know what you're looking for. I didn't see too much concrete info floating around after a cursory search, so I figured I'd throw it here in case some other wayward traveler needs it.
Creating and Using a Custom JSONEncoder
It all comes down to instructing your json.dumps() call to use a custom encoder. If you're familiar with the Django world, you've probably run into this with the DjangoJSONEncoder serializer. We essentially want to coerce Pandas and Numpy-specific types to core Python types, and then JSON generation more or less works. Here's an example of how to do so, with comments to explain what's going on.
import numpy
from json import JSONEncoder
class CustomJSONEncoder(JSONEncoder):
def default(self, obj_to_encode):
"""Pandas and Numpy have some specific types that we want to ensure
are coerced to Python types, for JSON generation purposes. This attempts
to do so where applicable.
"""
# Pandas dataframes have a to_json() method, so we'll check for that and
# return it if so.
if hasattr(obj_to_encode, 'to_json'):
return obj_to_encode.to_json()
# Numpy objects report themselves oddly in error logs, but this generic
# type mostly captures what we're after.
if isinstance(obj_to_encode, numpy.generic):
return numpy.asscalar(obj_to_encode)
# ndarray -> list, pretty straightforward.
if isinstance(obj_to_encode, numpy.ndarray):
return obj_to_encode.to_list()
# If none of the above apply, we'll default back to the standard JSON encoding
# routines and let it work normally.
return super().default(obj_to_encode)
With that, it's a one-line change to use it as our JSON encoder of choice:
json.dumps({
'my_pandas_type': pandas_value,
'my_numpy_type': numpy_value
}, cls=CustomJSONEncoder)
Wrapping Up
Now, returning and serializing Pandas and Numpy-specific data types should "just work". If you're the Django type, you could optionally subclass DjangoJSONEncoder and apply the same approach with easy serialization of your model instances.